So I’m not going to explain. I’m not going to make excuses for ignoring this blog for so long. I’m just going to go ahead and get started. And talk about some of the things I’ve learned and been looking into over the past year.
Node
Mainly, I’ve really gotten into Node.js. I was skeptical at first, but I’ve come around to realizing that it really does represent a more stripped-down, bare-bones method of web development. The community is massive and active — just see how many downloads per day NPM handles — and some of the work being done out there is really extraordinary. I’m especially excited about some of the new ES6 features now being offered by the platform. Integrated promises? Easily-extendable class structures (which I’ll admit have certain limitations, but make up for it with readability, at least compared to the other standard ways of making JS “classes”)? Sign me up.
(Speaking of NPM, I’ve actually published one or two modules of my own. They’re pretty simple and probably kind of outmoded at this point, but definitely learning experiences. I should probably talk about them on here at some point.)
Microservice Architecture
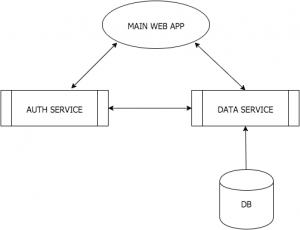
Hand-in-hand with the Node philosophy is the entire concept of microservices. The basic idea goes something like this: rather than have a single large web app that handles multiple tasks (like authentication and search indexing and view templates and whatnot), you have multiple web apps that interact with each other via REST calls. So rather than handling a login request with its own code, a web app will contact its Authentication app with the user’s login information, which will then do the work of checking the database and sending back a cookie and everything. The benefit to this approach is that it makes scaling — adding more servers or more resources to help a site handle more users — a lot easier. If your authentication process runs slow, for instance, you can simply add another instance of the Authentication app (either to an existing server or a new server) and have your main app load balance between the two.
While I’m sure this sort of architecture is old hat for a lot of people, it’s a new way of thinking for me. I’m currently going through the steps of designing a sort of content management system for businesses. I find I have to catch myself quite often going back to more conventional architecture. For instance, why bother having an integrated database service within the application when you can just have a Data Layer Microservice that the main app calls into? (This would also theoretically let me support multiple databases — which is a plus, since I don’t know what sort of infrastructure this might need to run on.) Well, if I’m going to do that, why not create an Authentication microservice app that interacts with the Data Layer microservice to handle those sorts of tasks?
Am I going too deep down the rabbit hole here? It’s possible. But I’m betting that the scalability of the approach will make up for any downsides.
The one big question that one has to worry about with this approach, of course, is security. How to make sure that a microservice only accepts input from our application and other related microservices. This especially becomes a concern if we’re working in an environment — say, like a cloud server solution — where we can’t know for certain that only authorized entities have access to the network. Even if that’s not the case, the paranoiac in me has too easy a time imagining some external hacker managing to insert or modify a request inside the local network and getting access to the Data Layer. Simple API keys might be vulnerable to a man-in-the-middle attack. I suspect my solution will probably involve a bunch of RSA certificates. More on this later, maybe.
JSON Web Tokens
Speaking of authentication, I’ve been looking into JSON Web Tokens, a new standard being pushed by Auth0, an authentication software-as-a-service which in itself seems promising for prototyping. Basically, it’s a standard way of writing the auth token one issues to a client in a manner that’s both more compact than previous XML-based token schemas and easily interpreted by multiple languages and frameworks. (I almost said auth cookie, but it seems that they’re avoiding using cookies as a way of getting past Cross-Origin Resource Sharing issues.) In particular, it seems to have been created with single sign-on across multiple applications in mind.
In general, I like it. It meshes with what I know about authentication, it’s compact, and it’s got room to expand things as one’s particular application might require. The one caveat again is — say it with me now — security. In its original form, it turns out that JWT revealed just a little too much to the client in a way that might compromise tokens signed with RSA certificates. So there’s obviously more work that needs to be done here. Still, the approach has enough promise that I’m considering using it in the CMS application I mentioned above, though perhaps in a slightly tweaked form.
That’s all for the moment, folks! Hopefully, you’ll be seeing a lot more of me on here in the near future.